Machine learning is no longer an unfamiliar concept to us; it has become an indispensable aspect of numerous projects. Currently, many developers are dedicated to crafting machine learning applications and projects that carry tangible value in the real world. These endeavors are confidently deployed to meet the ever-evolving demands of the market.
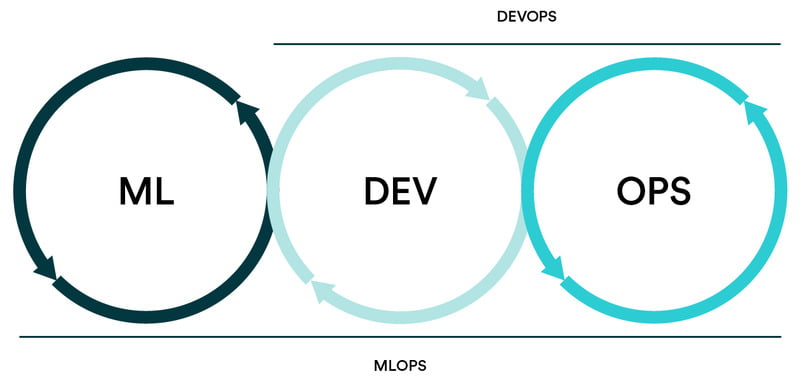
At this moment, the term “MLOps” emerges as a significant aspect of software development. MLOps is a part of the Machine Learning field, closely related to DevOps. MLOps is developed based on the principles and processes established in DevOps.
So, what are the differences between MLOps vs DevOps? How can we effectively bridge the two? Let’s discuss these issues with Nexle Corporation!
Definition of MLOps vs DevOps
What is MLops?
MLOps, short for Machine learning operations, refers to the methodology and processes that combine Machine Learning (ML) and Operations (Ops) in deploying and managing ML models in a production environment. It encompasses their maintenance and monitoring as well. MLOps is a collaborative function that brings together data scientists, DevOps engineers, and IT professionals.
Deploying machine learning applications or projects can be quite intricate. The development process is structured into distinct stages, encompassing data collection and preprocessing, model training, model tuning and optimization, model deployment in a production environment, post-deployment model monitoring and maintenance, and the incorporation of model explainability to understand its decision-making process.
For successful completion, diverse teams must collaborate seamlessly and exchange information efficiently. The data engineering team traditionally handles data collection and preparation, while the responsibility of training and fine-tuning the model is assigned to the data science and ML Engineering teams.
What is DevOps?
DevOps promotes a collaborative culture between developers and operators, encouraging effective teamwork. The term “DevOps” combines “Development” and “Operation,” reflecting its purpose of enabling a seamless workflow for software development, testing, and deployment. By implementing this approach, organizations can reduce product delivery time, enhance system stability, and improve infrastructure management flexibility.
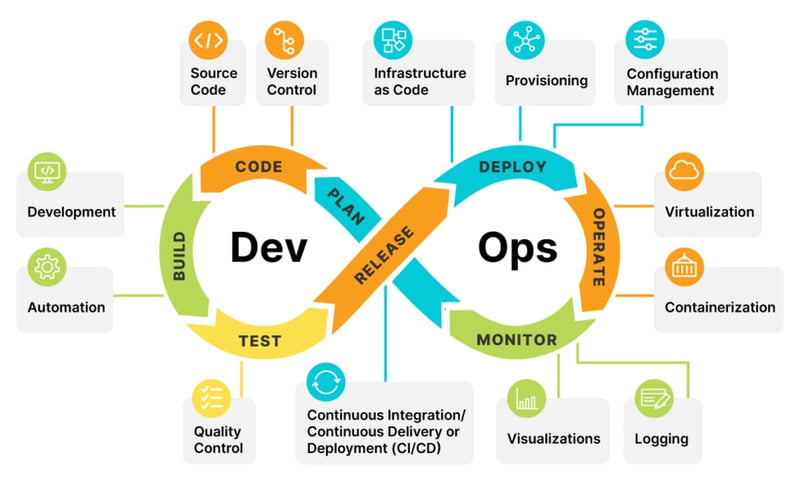
DevOps lifecycle
Cycle
DevOps and MLOps incorporate pipelines into their workflows, including a code-validate-deploy cycle. However, the MLOps process introduces additional stages specifically related to data handling and the development/training of machine learning models beyond the foundational steps found in DevOps – these supplementary steps involving data and machine learning result in minor differences between MLOps and traditional DevOps.
The terms “Data” and “Model” can often be unclear and open to interpretation, as their meaning can vary depending on the specific context and project objectives. However, in most cases, they refer to the process of data labeling, data transformation/feature engineering, and algorithm selection.
In the majority of machine learning projects implemented in today’s industry, machine learning algorithms are commonly applied in a specific manner referred to as “supervised learning.” Within this approach, a machine learning model undergoes training using available data. It is important to note that each data point within the dataset is accompanied by a corresponding “target” or “label” assigned to it. The model acquires knowledge and proficiency through exposure to such examples, enabling it to make predictions or classifications when presented with new, unseen data points.
Data transformation and feature engineering are necessary for machine learning because raw data is often insufficient for the machine learning model to understand and produce meaningful prediction or classification results. The machine learning model requires a specific structure of data to operate effectively. Furthermore, the choice of algorithm depends on the nature of the specific prediction problem.
The process of working with data and building machine learning models adheres to the “Cross-Industry Standard Process for Data Mining” (CRISP-DM). This widely adopted standardized process model is extensively utilized in the field of data science.
In overview, MLOps vs DevOps in the “Dev” and “Ops” deployment phases share some similarities or resemblances.
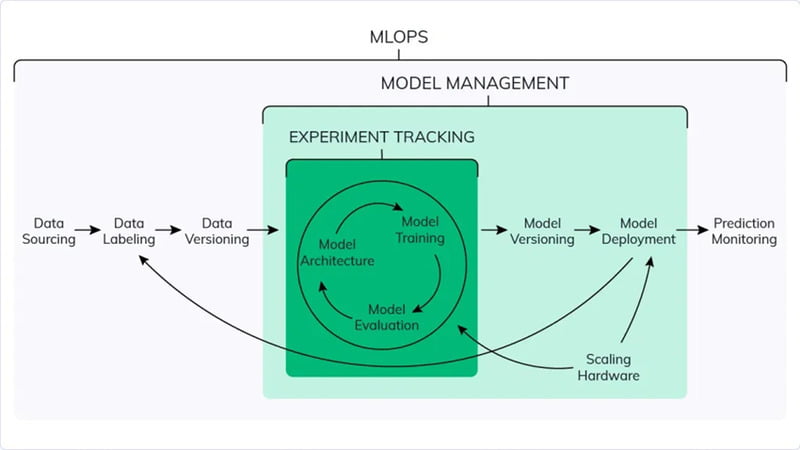
Development and CI/CD
In the realm of traditional DevOps, “code” refers to a compilation of developer-written commands and files used in software or application development. Once the source code is refined and edited, it is bundled into an executable file (referred to as an artifact), which contains compiled code or a functional application capable of running on a computer. This executable file is subsequently deployed within a production environment where it operates and fulfills its ultimate purpose, such as powering a web application or service. This process follows an optimized automation cycle, iterating until a final, polished product ready for use emerges.
In the process of MLOps, source code is utilized to construct and train a machine learning model. The resulting artifact is a standardized file that can take input data and generate predictions or outcomes based on the trained model. To assess its performance, the validation process involves evaluating the model using a separate test data file, one that it hasn’t encountered during training. This iterative cycle, similar to DevOps, continues until the model attains a specific level of accuracy and performance.
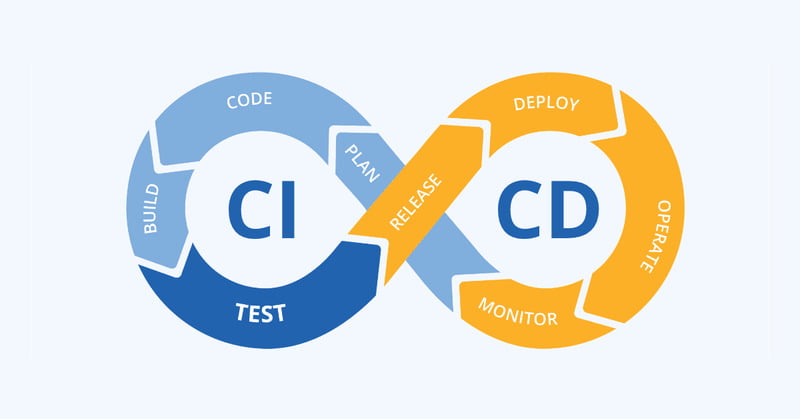
Version Control
In a traditional DevOps pipeline, version control typically focuses on tracking changes in source code and related source code components, such as application code, documentation, executable files, and deployment instructions.
In an MLOps pipeline, there are numerous aspects to monitor. The process of constructing and training a machine learning model, including testing and refining it, follows an iterative cycle where data scientists and developers conduct multiple experiments to enhance the model’s performance. This is particularly crucial in the field of machine learning because various factors, such as training data, model architecture, and hyperparameters can influence a model’s efficacy.
The components and metrics of each experimental run need to be tracked to ensure the model’s consistency and reusability.
Read more: Agile vs DevOps: What’s the Difference?
Monitoring
There is another important factor to monitor in the MLOps process, and that is “model drift.” “Model drift” occurs when the predictive capabilities of models degrade due to changes in the real-world environment. Data is constantly changing; therefore, to ensure that the model continues to perform effectively, we need to update the model regularly. Models trained on old data may not work well with future data, especially when the data exhibits seasonality. Therefore, maintaining and retraining the model periodically is essential.
Roles and responsibilities
Roles and responsibilities have some minor differences between MLOps vs DevOps. Moreover, during the software development and deployment process, team members may encounter changes in their roles and responsibilities based on the nature of the project.
In DevOps, software undergoes a collaborative process where dedicated software engineers craft the source code for applications or systems. DevOps engineers then shift their focus towards deployment and establishing a streamlined Continuous Integration/Continuous Deployment (CI/CD) pipeline. This pipeline automates application deployment and testing procedures.
In MLOps, projects often involve constructing and deployment of machine learning models. In this capacity, data scientists are responsible for writing code to build and train machine-learning models using data. Subsequently, MLOps engineers or machine learning engineers focus on deploying and monitoring these models in a production environment. Their goal is to ensure the models’ effective operation and ability to handle real-world data.
Differences Between DevOps vs MLOps
MLOps vs DevOps are crucial methodologies for organizations seeking success in software development and machine learning. Here are some key differences you need to understand:
DevOps
- DevOps is a method that helps optimize and manage the software development process from start to finish.
- DevOps emphasizes close collaboration and interaction between teams throughout this process to ensure the performance and reliability of the application.
- It prioritizes ensuring the efficient and reliable operation of the application.
- It focuses on automating tasks related to software testing and deployment.
- Tasks include deploying applications or source code to the production environment and managing infrastructure configuration.
MLOps
- Focusing primarily on building, training, and deploying machine learning models.
- Emphasizing data management related to machine learning and monitoring model versions.
- Prioritizing ensures that machine learning models perform well and remain stable in production environments.
- The tasks of MLOps include hyperparameter tuning and feature selection during development.
- Tasks related to explaining the model and ensuring fairness in using machine learning models.
You should understand that these two methods are completely separate and bring significant benefits to businesses. Therefore, many large enterprises will combine both into their software development processes.
So how can you integrate these two methods to make them work together effectively?
Integrating MLOps with DevOps
To effectively connect MLOps vs DevOps, you can follow these suggestions:
- To foster close collaboration among team members, bringing together various experts such as data scientists, operations teams, and development teams is important. Building strong working relationships and promoting open communication among these teams is crucial.
- Clear and efficient channels should be established to convey information effectively between different working teams. The aim is to prevent any loss or misunderstanding of data, ensuring that everyone can work based on the communicated information.
- Automating workflow processes like testing, validation, and model deployment is essential for minimizing errors, improving work efficiency, and ensuring the consistency and reliability of machine learning models in production. Both DevOps and MLOps recognize the importance of automation in enhancing work processes.
- The current process isn’t the best. It’s important to regularly assess and enhance the workflow for better performance and increased efficiency. This will improve both work processes and the application of new technology in MLOps and DevOps.
- Establishing DevOps monitoring and feedback loops ensures that applications and models function as intended. This helps enhance performance, stability, and functionality.
Read more: DevOps vs DevSecOps: What’s the Difference?
In summary, MLOps isn’t an entirely new revolution in the realm of application development and management. Rather, it serves as a specialized DevOps implementation optimized for machine learning projects. By bridging the gap between data science and information technology, MLOps ensures that developing, deploying, and managing machine learning models is efficient and reliable. In essence, MLOps offers a specific approach to applying the principles and processes of DevOps to the field of machine learning.
Despite some minor variations in their processes, both MLOps vs DevOps place significant importance on collaboration, automation, and continuous monitoring. These shared principles aim to guarantee the quality and performance of applications and models. By combining the strengths of these two fields, powerful and adaptable machine learning solutions can be developed to meet the ever-growing demands of the modern digital landscape.
We hope that the information from Nexle Corporation can answer your questions!



